酷睿Ultra X9 388H首发!本地运行大模型流畅不卡,生成速度创纪录。
【ZOL原创报道】1月底,英特尔酷睿Ultra X9 388H处理器正式进入专业评测视野。作为第三代酷睿Ultra家族的旗舰移动SoC,其在CPU架构、能效比与核显性能上的跃升已广受关注;而此次深度评测进一步揭示了一个关键事实:AI本地化能力正从“能跑”迈向“好用”——该处理器CPU+NPU+GPU协同算力达180TOPS,其中GPU贡献120TOPS,NPU虽仅提升2TOPS,但得益于矩阵引擎规模扩大与指令集优化,实际推理吞吐效率远超纸面数值。这标志着x86平台首次在轻薄本形态下,系统性具备了支撑主流大语言模型本地部署的硬件基础。
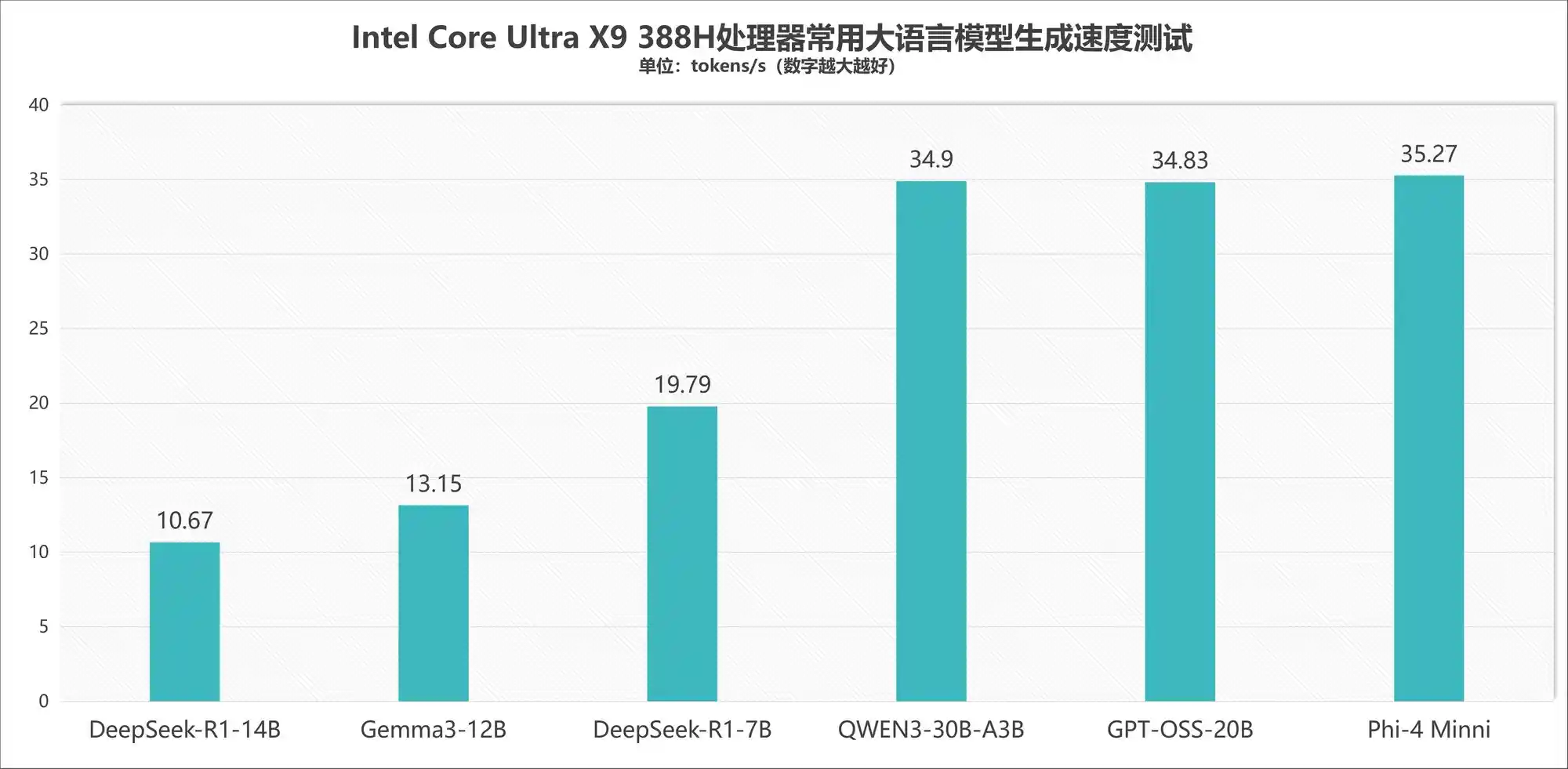
那么,理论算力能否转化为真实用户体验?答案是肯定的。在大语言模型实测环节,酷睿Ultra X9 388H展现出清晰的性能边界与务实的技术路径:运行DeepSeek-R1-14B稠密模型时,生成速度稳定在10.67 tokens/s,画面流畅度足以支撑日常交互式使用——这意味着14B已成为当前x86轻薄平台本地运行稠密模型的实际天花板。值得注意的是,这一结论并非技术保守,而是对内存带宽、显存容量与功耗墙三重约束的客观回应。当模型参数突破14B,单纯堆叠参数已难以为继,转向MoE(Mixture of Experts)架构成为必然选择。

实测六款主流开源模型印证了这一判断:Gemma 3-12B达13.15 tokens/s,DeepSeek-R1-7B达19.79 tokens/s,而Qwen 3-30B-A3B(MoE结构)、GPT-OSS-20B及Phi-4 Mini三款模型均突破34 tokens/s,最高达35.27 tokens/s。这一反差极具启示意义——它说明,面向终端用户的AI算力竞争,已不再只是“参数军备竞赛”,而是转向“架构适配力”的比拼。英特尔通过强化GPU张量单元与NPU调度效率,成功将MoE稀疏激活的优势转化为可感知的响应速度,这比单纯提升峰值算力更具现实价值。
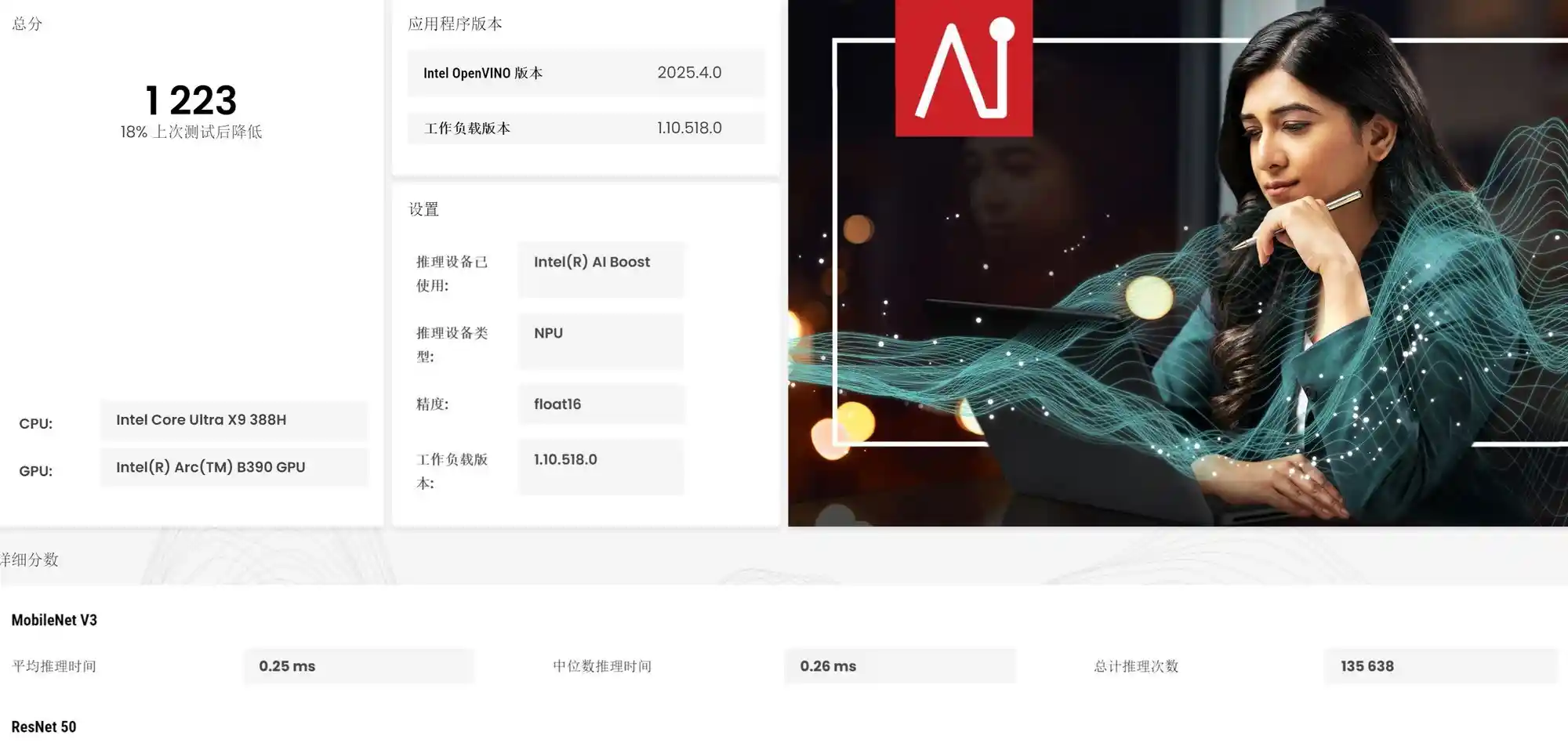
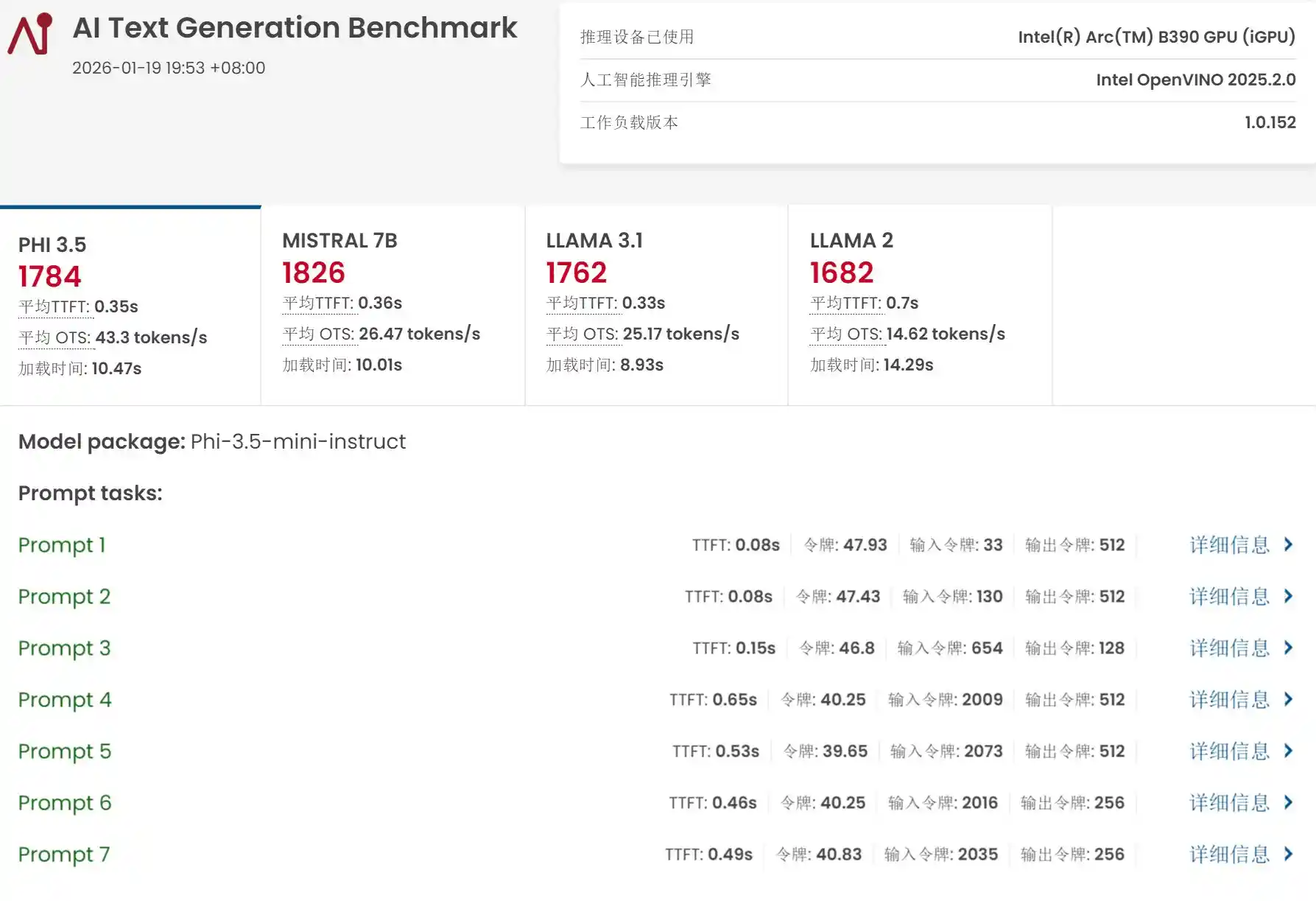
更值得强调的是,在UL Procyon AI专项测试中,锐炫B390核显Float16算力评分飙升至1495分,较上一代提升近700分,增幅约78%;NPU评分亦达1223分,提升超300分(+32%)。尤为关键的是,上一代平台因显存带宽与AI加速单元能力不足,甚至无法完成UL Procyon的大模型生成测试;而X9 388H不仅顺利通关,更在PHI 3.5、MISTRAL 7B、LLAMA 3.1、LLAMA 2四项基准中分别实现43.3、28.47、25.17、14.02 tokens/s的生成速率。这组数据背后,是英特尔在IP集成、内存子系统重构与AI Runtime优化上的系统性突破,而非单点技术改良。
综合来看,酷睿Ultra X9 388H的意义已超越传统处理器升级范畴:它首次让一台厚度不足16mm、重量低于1.5kg的轻薄笔记本,真正具备了本地运行14B级稠密模型与30B级MoE模型的能力。对于开发者、科研人员及AI爱好者而言,这意味着无需依赖云端API即可完成模型微调、提示工程验证与私有知识库问答等核心工作流;对产业而言,则预示着端侧AI应用生态正加速从“演示原型”走向“生产可用”。当然,挑战依然存在——如显存容量对长上下文支持的限制、NPU与GPU间任务调度的成熟度,以及Windows平台AI工具链的完善程度。但毫无疑问,{}这一天,x86端侧AI已跨过临界点,进入实质性落地阶段。