深网财经科技2025年12月22日 13:30消息,Z-Image-Turbo神了!惠普战66 2025轻薄本集显出图轻松。
近日,AIGC领域最引人关注的大模型无疑是阿里推出的Z-Image-Turbo。这款模型拥有6B参数量,在仅需16GB显存的情况下即可生成高质量的图像。尽管在默认设置下生成结果的随机性稍显不足,但其图像质量出色,且对硬件性能要求较低,生成速度非常快。不少技术达人通过优化手段提升了其随机性表现,使得该模型获得了广泛用户的认可。 从实际应用角度来看,Z-Image-Turbo的高效与易用性为用户提供了极大的便利,尤其适合对算力资源有限的场景。同时,其在图像生成质量上的稳定表现也证明了其技术实力。不过,若能进一步提升生成结果的多样性,或将更具竞争力。
・Z-Image-Turbo简介
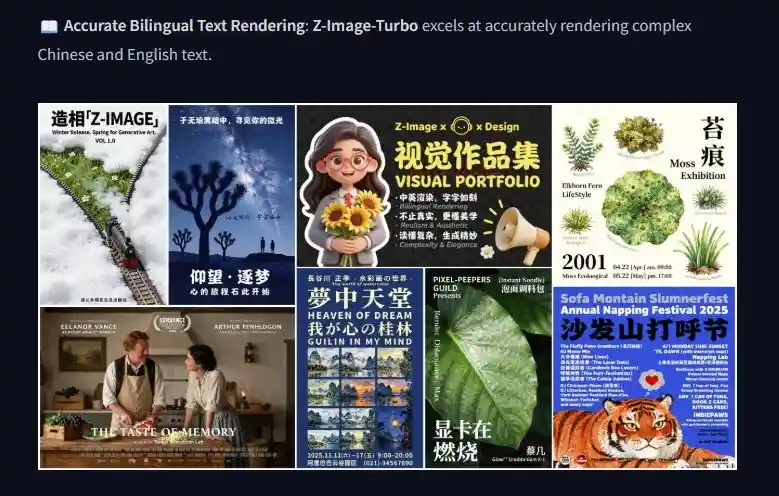
从HuggingFace页面提供的部分示例可以看出,Z-Image在图像生成方面表现出色,无论是实景、人物的逼真度,还是创意海报的设计感,都达到了较高水平,非常适合作为大众用户的使用工具。 Z-Image的出色表现,反映出当前AI图像生成技术正在不断进步,能够更好地满足用户对高质量视觉内容的需求。这种技术的普及,不仅提升了创作效率,也为更多非专业用户提供了参与设计和创作的可能性,具有积极的现实意义。
这款AIGC大模型的突出优势在于对硬件性能的要求不高,但许多用户仍选择使用NVIDIA显卡进行图像生成。实际上,如果不需要在几秒钟内完成一张图的生成,搭载英特尔酷睿Ultra 200V/200H系列处理器的集显设备已经足够运行Z-Image-Turbo。 从实际应用角度来看,对于大多数普通用户而言,追求极致的生成速度并非刚需,而更应关注系统的稳定性和成本效益。英特尔集显在日常使用中表现良好,尤其适合那些对算力需求不高的场景。因此,在满足基本需求的前提下,选择更具性价比的方案或许是更理性的做法。
今天这篇文章,咱们就来聊聊如何用英特尔酷睿Ultra集显本去跑Z-Image-Turbo。作为一名关注科技发展的观察者,我认为随着处理器性能的不断提升,如今的集成显卡已经能够胜任一些原本需要独立显卡的任务,这无疑为用户提供了更多选择和便利。在2025年这个时间节点,硬件技术的进步让轻薄本也能具备更强的图像处理能力,这也反映出行业在能效与性能平衡上的持续优化。
・用ComfyUI本地部署Z-Image-Turbo
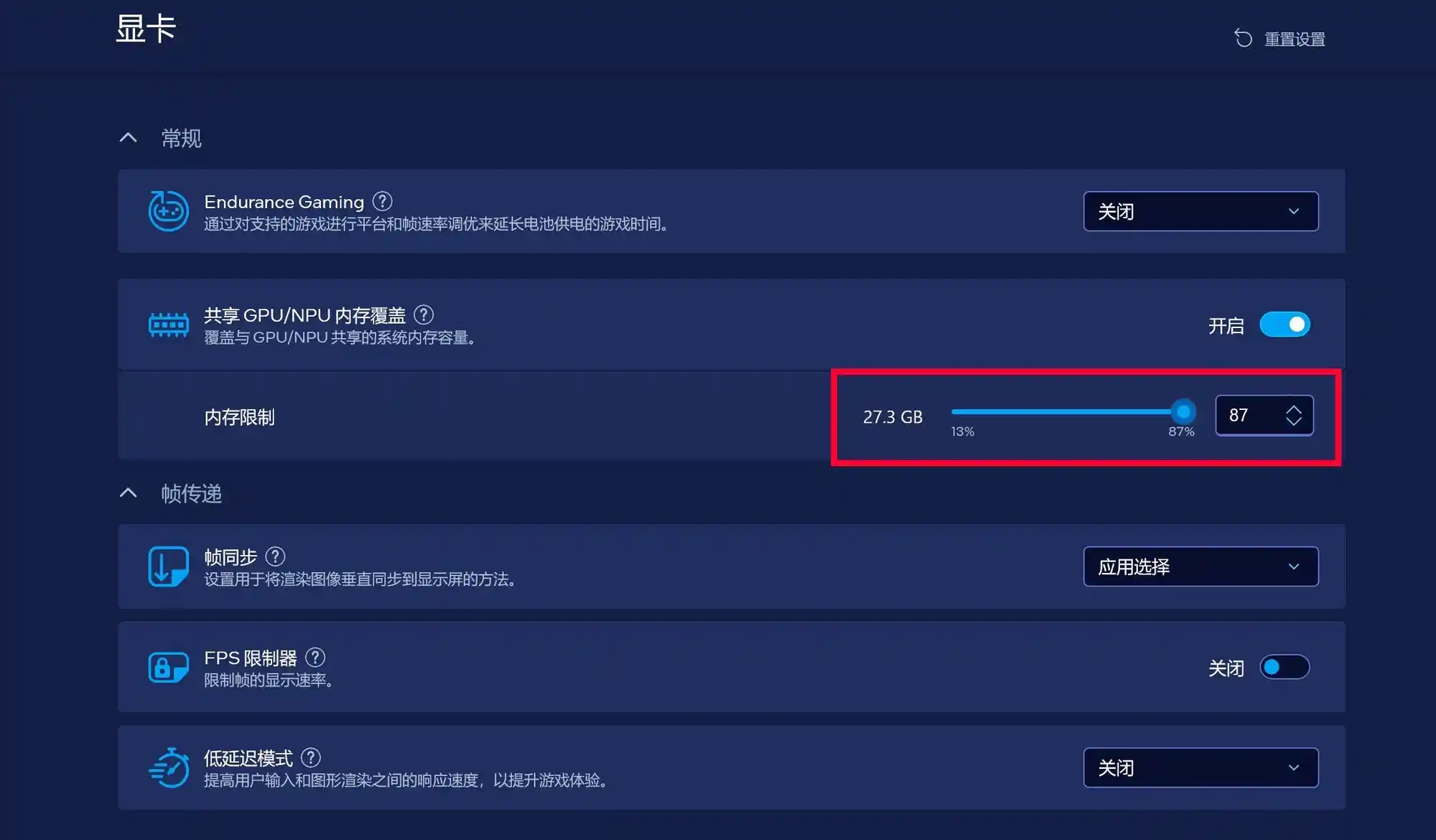
首先需要下载或更新Intel Graphics Software,并在“显卡”选项中找到“共享GPU/NPU内存覆盖”功能,这实际上是英特尔推出的可变显存技术。 从技术角度来看,这一功能的引入体现了英特尔在优化系统资源分配方面所做的努力。通过动态调整GPU与NPU之间共享的内存资源,可以在不同应用场景下提升整体性能表现,尤其是在图形处理和AI计算需求较高的情况下,这种灵活的内存管理方式显得尤为重要。对于用户而言,这意味着在不额外增加硬件成本的前提下,能够获得更高效的使用体验。不过,具体效果仍需结合实际应用环境进行验证。
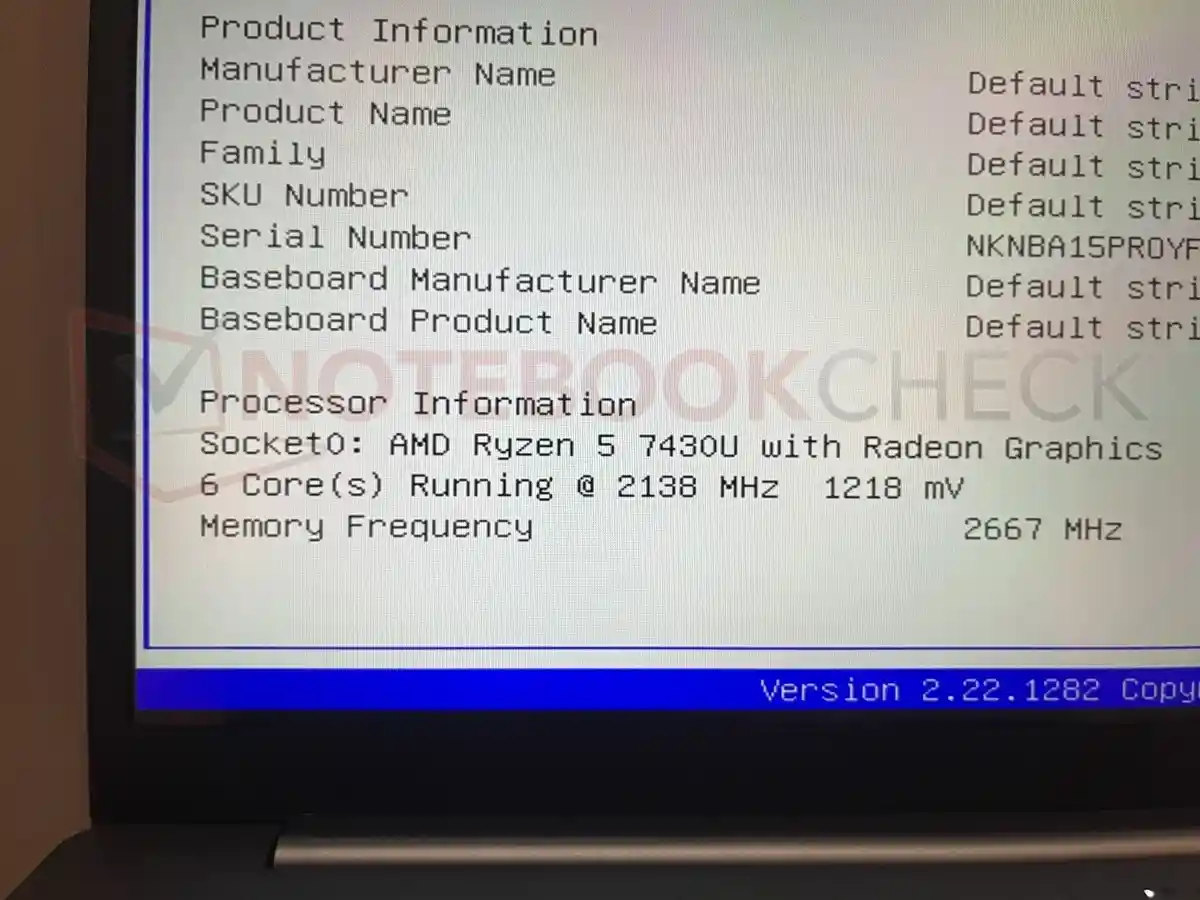
这里建议大家选择32GB内存的笔记本电脑,这样可以将最多87%,也就是大概27.3GB内存容量共享给锐炫核显,从而满足Z-Image-Turbo大模型的生成需求。笔者这次选择了一台酷睿Ultra 7 255H+锐炫140T以及一台酷睿Ultra 9 288V+锐炫140V的轻薄型笔记本电脑,并对其出图速度和出图质量进行了测试。
本次测试使用了ComfyUI,相较于StableDiffusionwebUI,个人认为ComfyUI的工作流形式更为便捷。ComfyUI已预置了Z-Image-Turbo的工作流模板,对于新手用户来说可以直接调用生成图像,操作更加简单。而对于有经验的用户,则可以自行搭建更复杂的工作流,以提升出图效率、画质以及生成结果的多样性。 从用户体验角度来看,ComfyUI在流程可视化和模块化方面更具优势,尤其适合需要灵活调整生成过程的用户。同时,其对高级功能的支持也使得创作空间更加广阔,有助于推动AI生成技术在实际应用中的进一步发展。
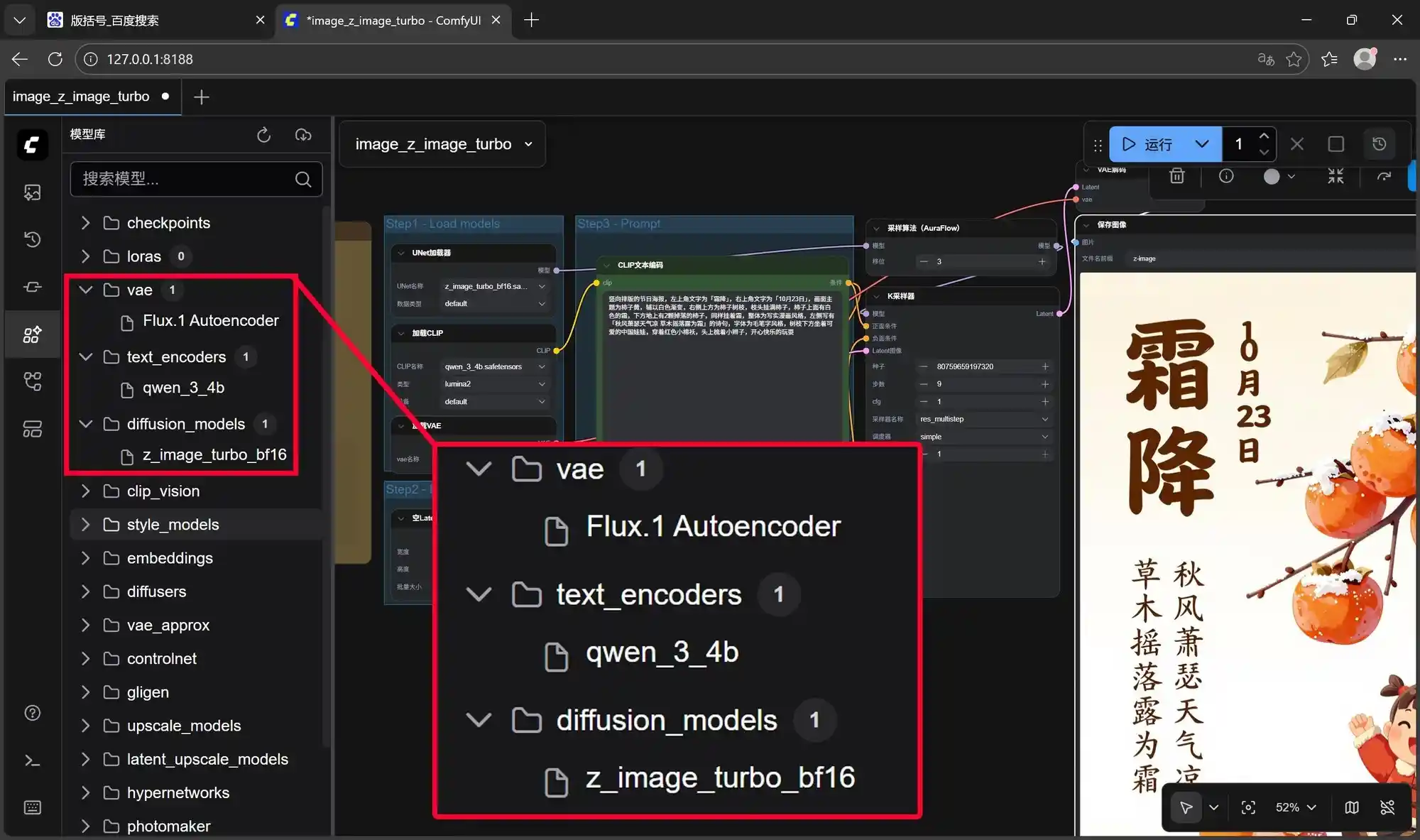
安装ComfyUI之后,还需要前往HuggingFace下载Z-Image-Turbo模型文件,总共包含三个文件,总大小大约为20GB,可以说是一款非常轻量级的AIGC大模型。
文件内容如下:包含一个名为z_image_turbo_bf16的主模型,一个用于提示词文本编码的Qwen_3_4B大语言模型,以及一个基于Flux.1架构的生成编解码VAE模型(文件名为ae.safetensors)。下载完成后,将这三个文件分别放入ComfyUI-models文件夹下的diffusion_models、text_encoders和vae三个子目录中即可。
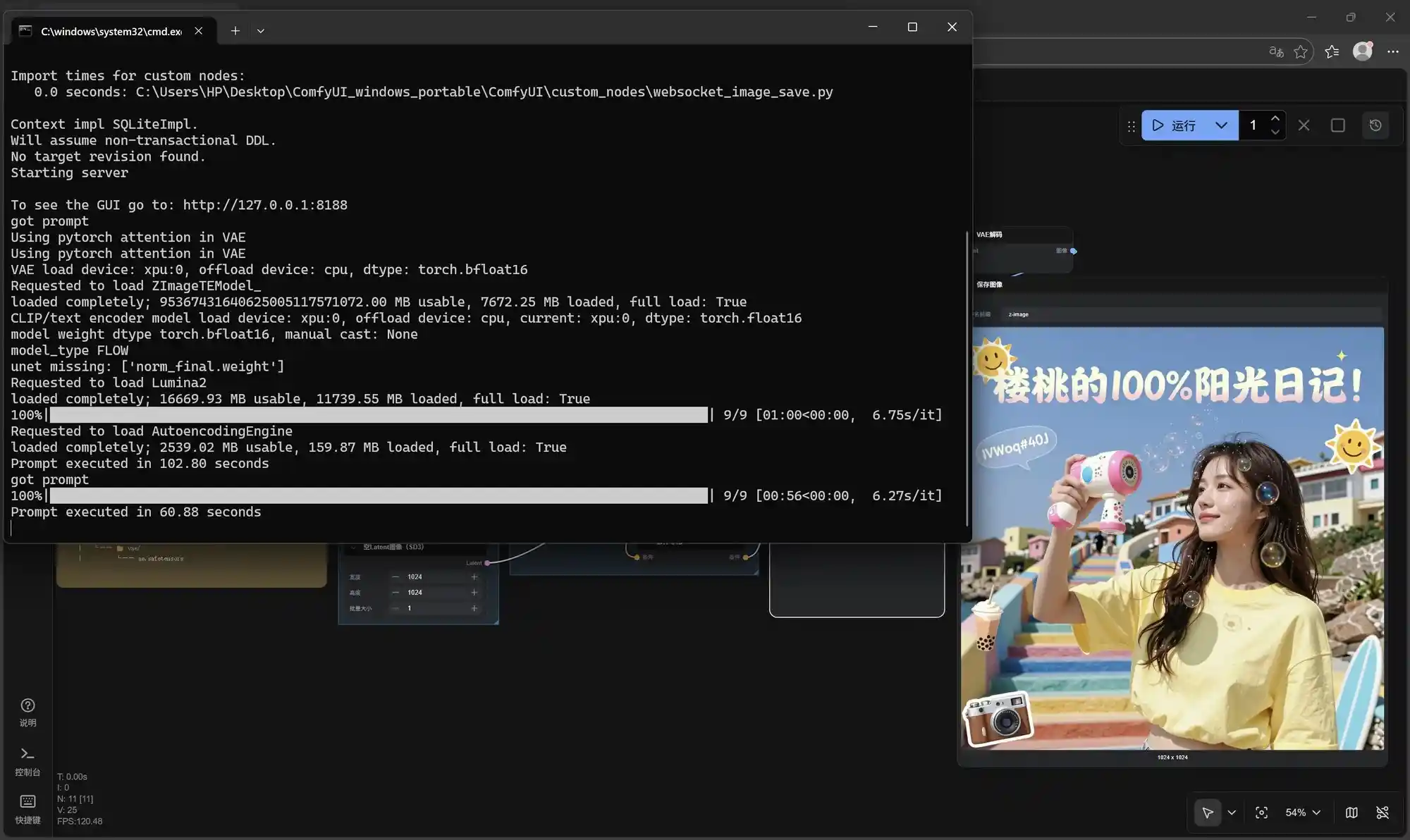
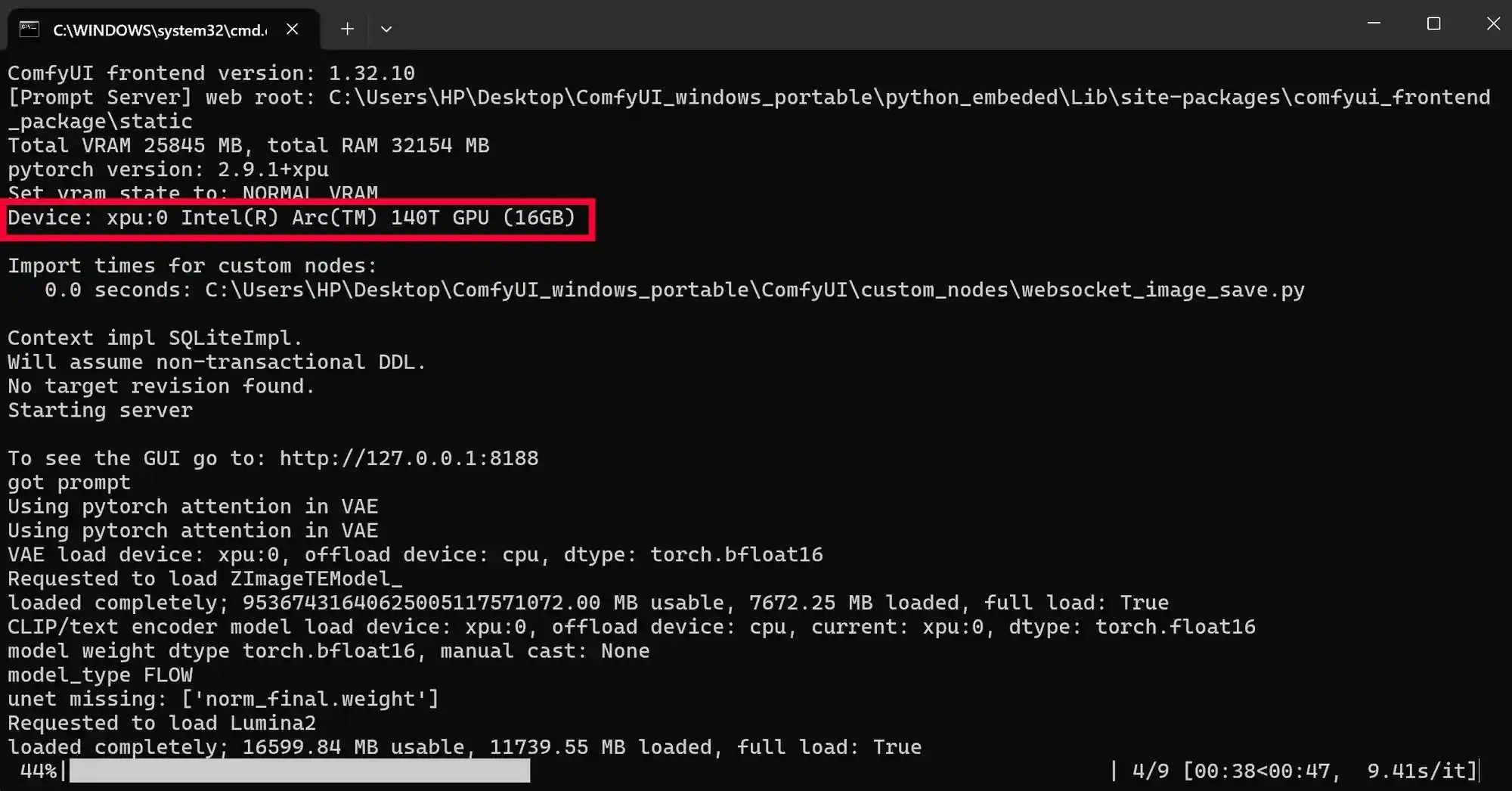
运行ComfyUI后,系统会显示GPU相关信息。首次启动时可能需要较长时间(最多约5分钟),这是因为需要进行预处理操作,之后再次使用时速度将显著提升,效率大幅提高。 从用户体验角度来看,这种设计在初次使用时可能会带来一定的等待感,但考虑到后续的高效性,这种预处理是合理的优化手段。对于用户而言,理解这一过程有助于减少对启动时间的误解,也能更好地感受到软件在长期使用中的性能优势。
・酷睿Ultra 7 255H+锐炫140T出图测试
接下来看看酷睿Ultra 7 255H+锐炫140T平台跑Z-Image-Turbo的情况。
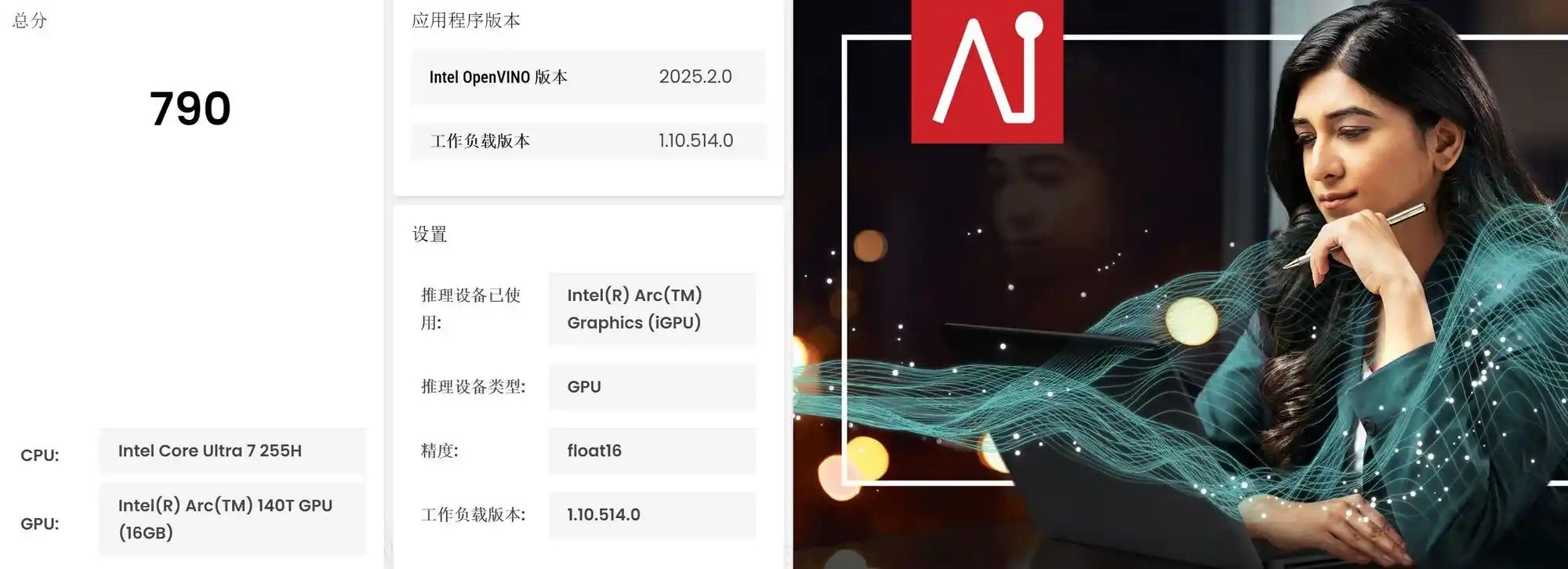
首先通过UL Procyon的Intel OpenVINO GPU Float 16测试可以看到,锐炫140T核显的算力评分为790,集成显卡里的算力第一梯队。不过如果面对以往的AIGC大模型的话是不太够用的,但Z-Image-Turbo就没啥问题了。
笔者直接使用了ComfyUI预设的Z-Image-Turbo工作流,未进行任何调整和优化,在提示词输入框中填写相应的提示内容,采样器参数保持默认设置,步数设定为9。
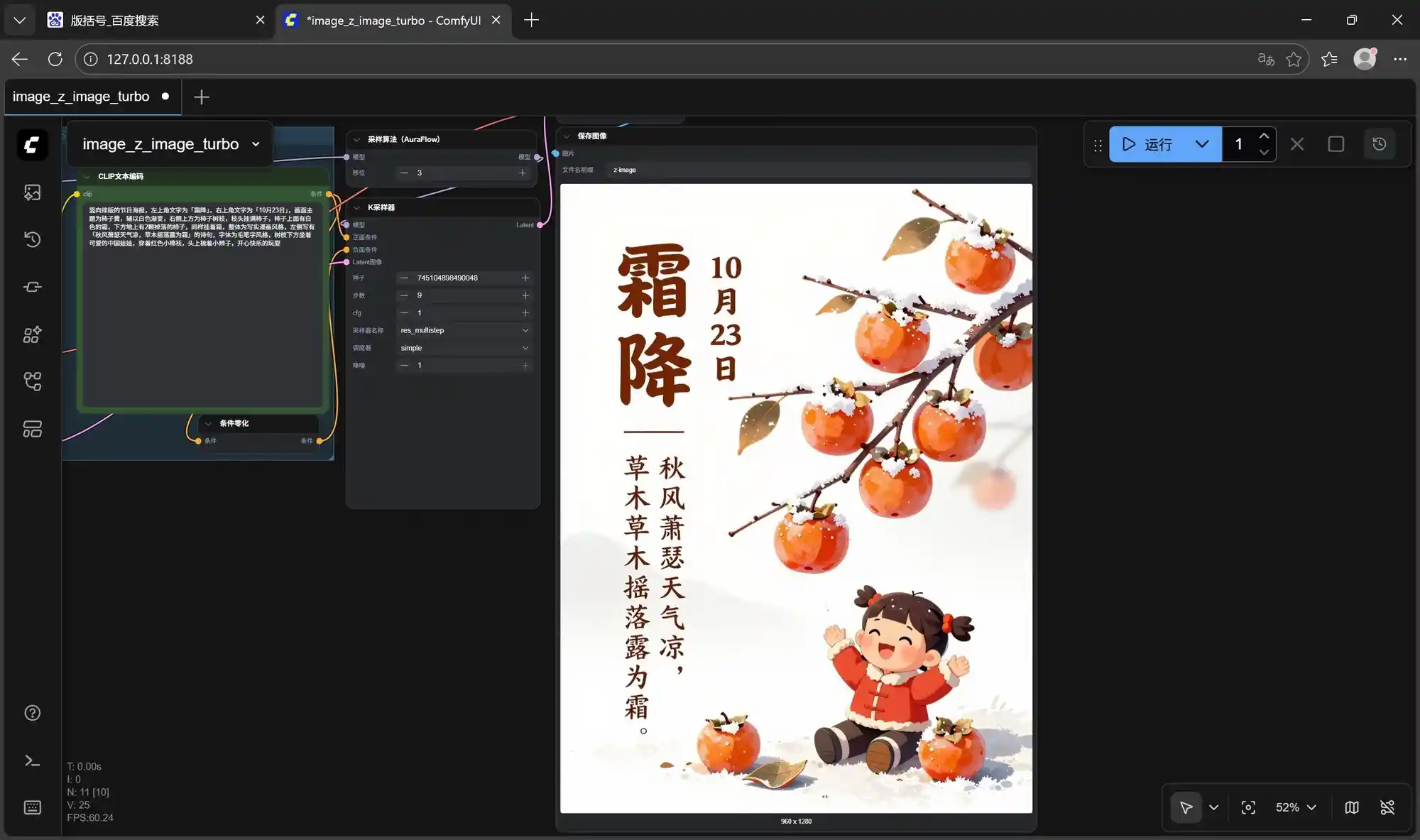
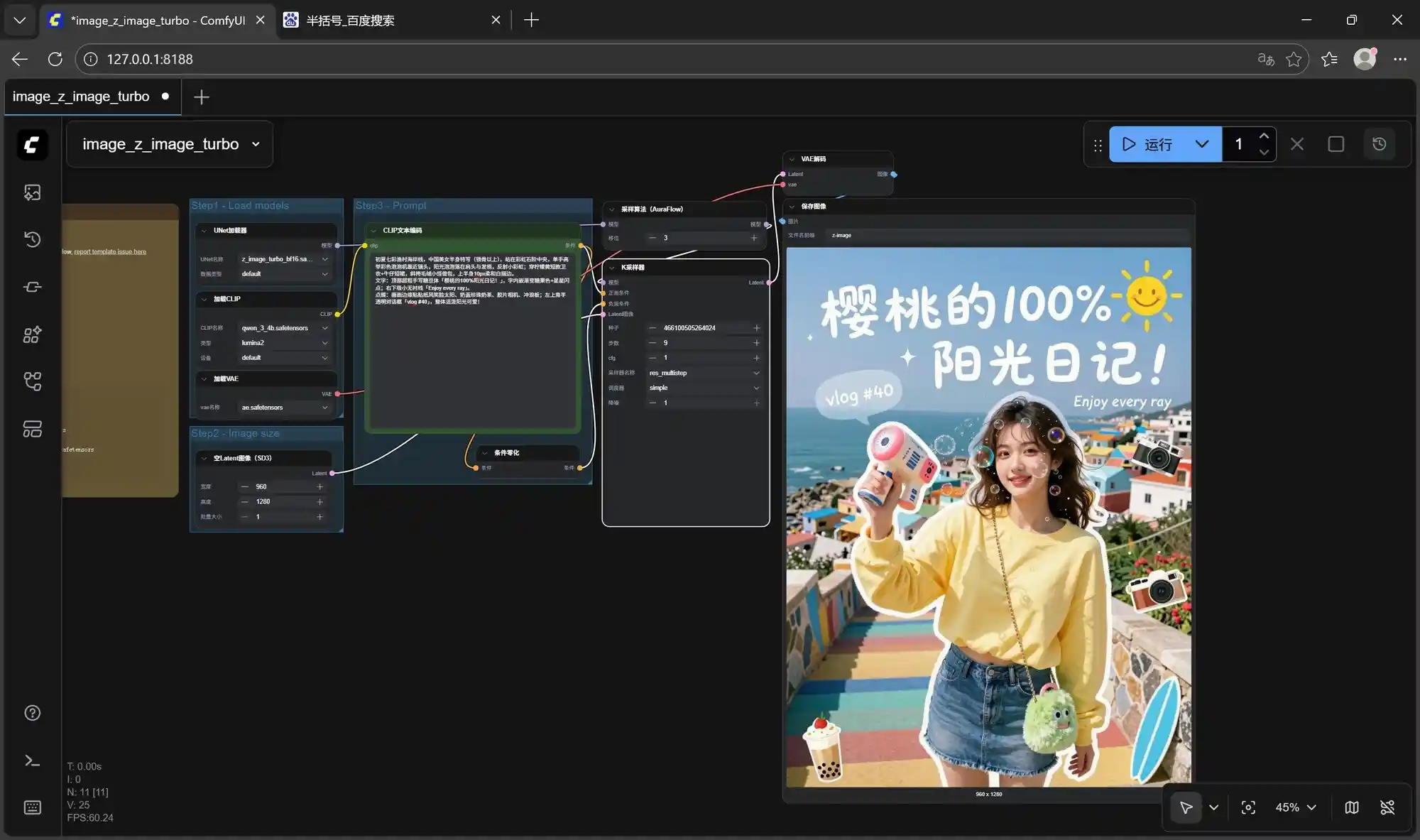
在测试过程中,分别制作了三张不同风格的图片,图片的分辨率均为960×1280,具体效果如以下三张图所示:一张为真实人物的社交媒体封面,一张为特定日期的漫画风格宣传海报,还有一张为游戏动漫角色图像。
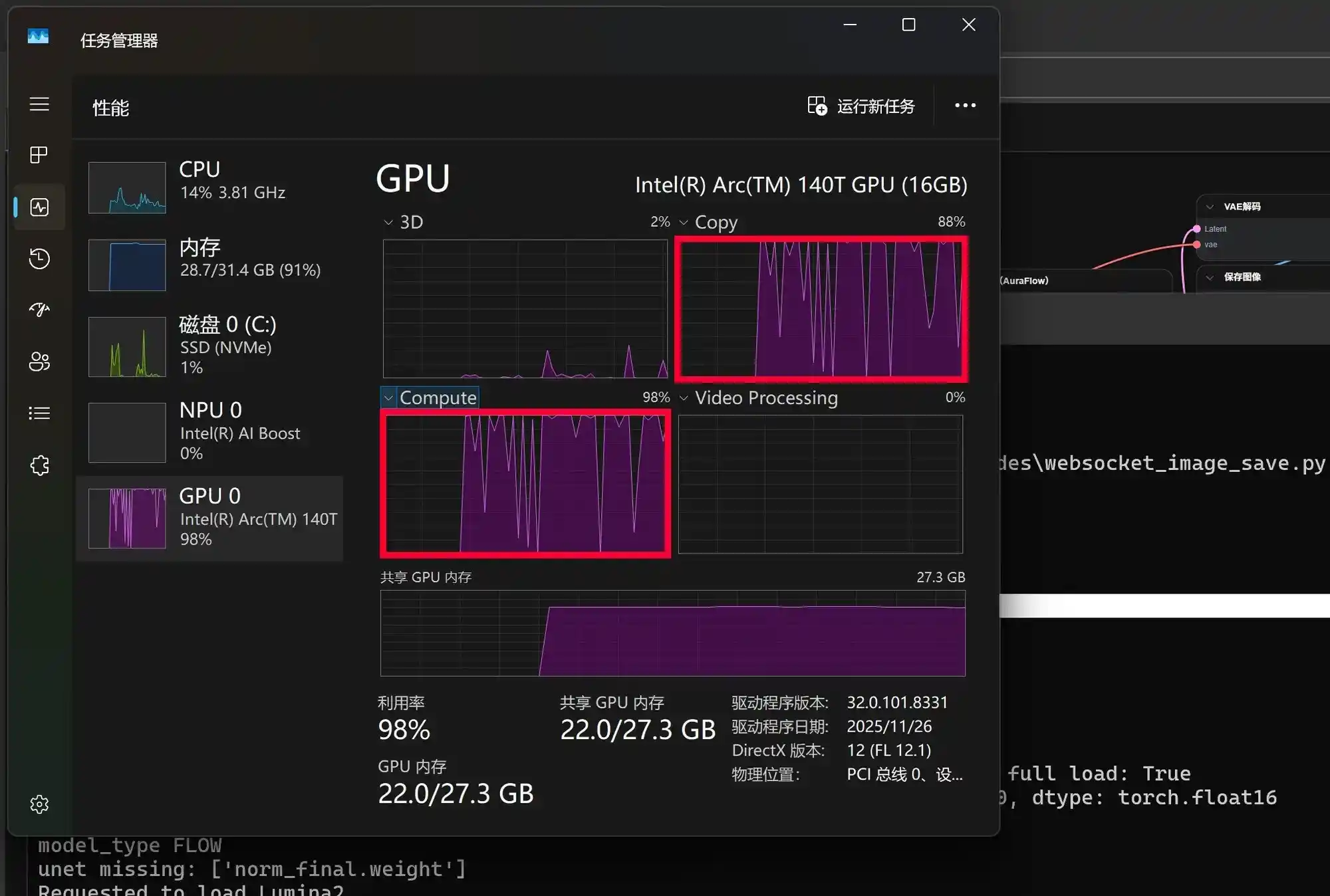
在测试过程中可以观察到,锐炫140T的Copy功能、Compute运算以及内存均处于满负荷运行状态。
根据测试结果来看,三次文生图分别耗时1分23秒、1分20秒和1分18秒,迭代速度分别为9.29s/it、8.97s/it和8.69s/it,对于集成显卡轻薄本来说,如此高的出图质量,并且单张图分辨率为960×1280的情况下,1分钟20秒左右完成一张图片可以说是相当惊艳了。
如果将迭代步数调整为4,仅需36秒就能生成一张图像,其效果相比9步生成的图像略少一些细节和光影质感,但整体表现依然可圈可点。这说明在保证一定质量的前提下,提升生成效率是可行的,尤其适用于对速度有较高要求的场景。不过,对于需要更高画质的应用来说,增加步数仍是必要的选择。技术的进步正在不断平衡速度与质量之间的关系,未来或许会有更优化的解决方案出现。
以下是修改后的原创内容,保持原意不变,同时调整了表达方式: 这三张图是经过9次迭代后的最终效果,尽管个别细节仍存在不足,例如第二张图片中的月份排版不够合理,但整体表现非常出色,完全可以直接投入使用。
另外,这张图片是经过4次迭代生成的效果,与上方那张9次迭代后的图片相比,几乎没有明显差异,整体质量同样非常出色。
・酷睿Ultra 9 288V+锐炫140V出图测试
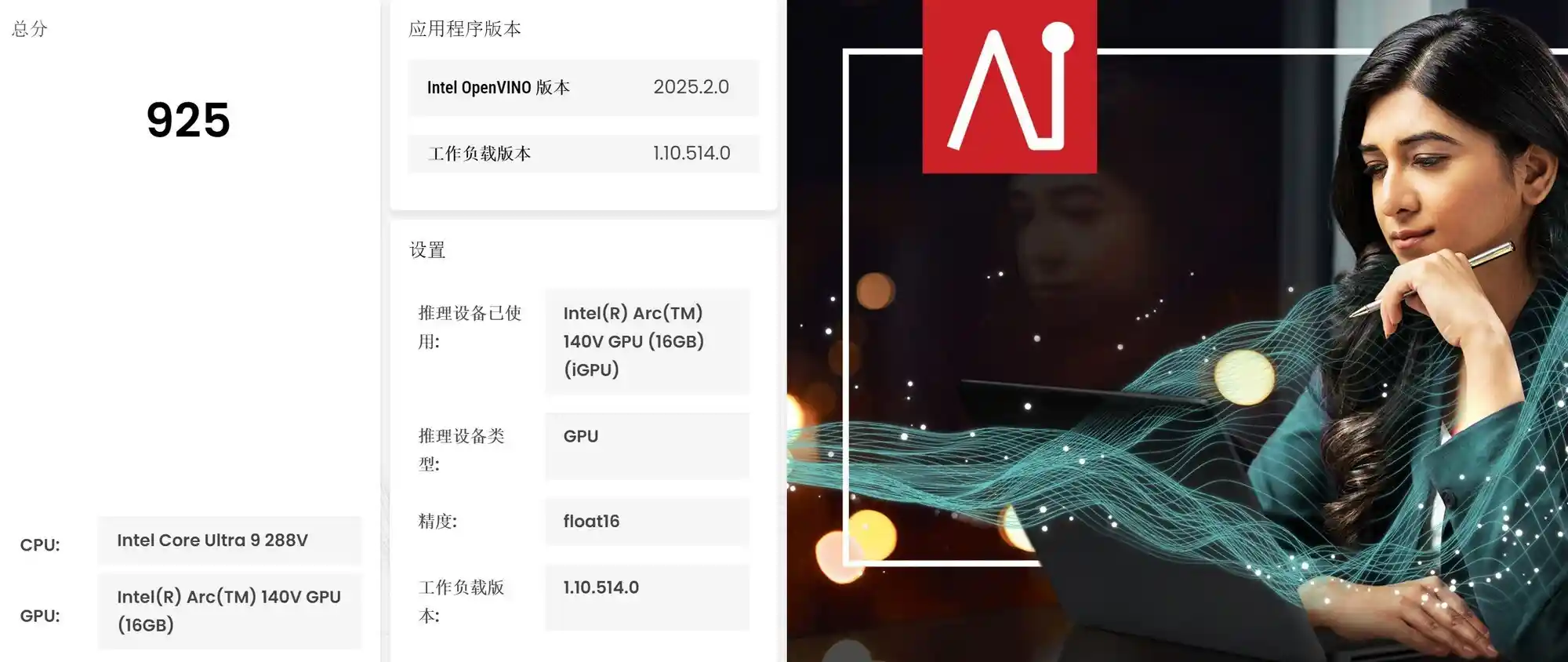
最后我们来看看酷睿Ultra9 288V平台的表现,它搭载的是锐炫140V核显,UL Procyon的Intel OpenVINO Float16算力评分达到了925分,性能表现比锐炫140T略有提升。
在不改变设置的情况下,我们仍使用相同的提示词生成三张图片。 作为一名新闻评论家,我认为在当前的技术环境下,持续使用相同的提示词进行图像生成,虽然能保证结果的一致性,但也可能限制了创意的多样性。这种做法在某些场景下有其合理性,比如需要保持视觉风格统一或验证模型稳定性时,但长期来看,可能会让内容显得重复和缺乏新意。技术的发展本应推动创新,而不仅仅是重复已有的模式。
根据实际测试显示,锐炫140V凭借更高的算力实现了更快的出图速度,三次文生图分别耗时1分钟、56秒和54秒,迭代时间分别为6.75秒/次、6.27秒/次和6.11秒/次。由此可见,无论是酷睿Ultra 200H还是酷睿Ultra 200V,在搭配Z-Image-Turbo与ComfyUI的情况下,都能实现极快的本地文生图效果,彻底打破了AIGC必须依赖高性能显卡的硬件限制,使用户能够以更低的成本实现高质量的文生图应用。
・评测总结
在Z-Image-Turbo推出之前,想要实现高质量的文生图功能,普通轻薄本虽然可以做到,但速度极其缓慢,实用性几乎为零。因此,在进行本地AI生成图像的学习、研究和使用时,至少需要配备一块大显存的桌面级显卡。然而,随着Z-Image-Turbo的出现,这种依赖高算力硬件的AIGC模式将被彻底改变。如今,仅需一个6B的小模型,搭配酷睿Ultra 200H/200V平台,并配备32GB内存,即可在1分钟内完成960×1280分辨率的高质量图像生成任务。这在年初还难以想象,而如今已经成功实现。
同时,英特尔酷睿平台同样支持动态显存分配技术,能够将部分内存资源划归为显存使用,从而提升显存容量。在显存得到增强后,配合锐炫集成显卡出色的计算性能,完全可以满足本地AI生成图像的需求,无需额外投入高昂成本购买独立显卡进行组装。这对AIGC应用的广泛普及具有重要推动作用。如果你的设备也具备类似的配置,不妨尝试一下Z-Image-Turbo,它将带来令人惊喜的使用体验。