字节跳动发布Seedance 2.0,称生成结果仍有瑕疵,仍需优化。
2月12日,豆包视频生成模型Seedance 2.0正式发布,并已全面接入豆包和即梦产品,同时在火山方舟体验中心上线。这一更新标志着视频生成技术在实际应用中的进一步深化,也为用户提供了更便捷、高效的创作工具。随着AI技术的持续进步,这类模型的普及将推动内容生产方式的变革,提升行业效率,同时也对内容质量与创新提出了更高要求。
目前,Seedance 2.0 对以真人图像或视频作为主体参考进行了限制,如需使用真人作为参考对象,必须经过本人的验证或获得其授权。

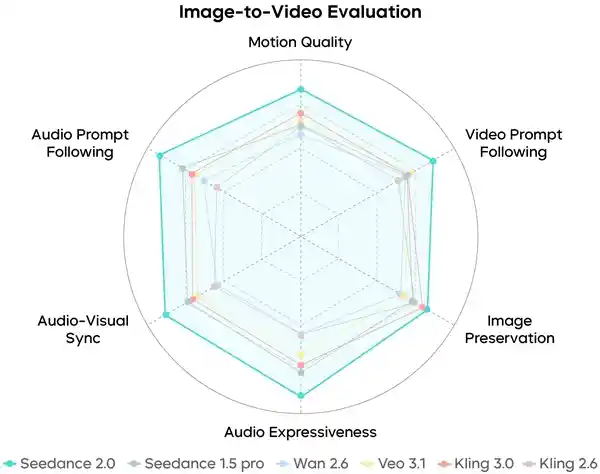
据字节跳动介绍,为全面评估模型在多模态场景的综合能力,团队协同影视领域专家,建立覆盖音视频生成、参考及编辑场景的综合评测集及相关评测标准。
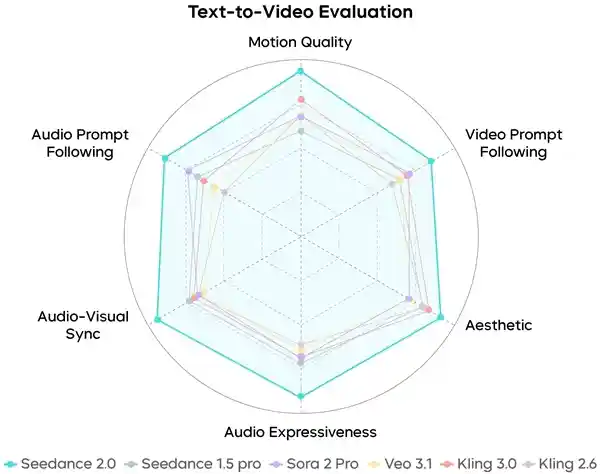
文生视频能力评测
图生视频能力评测
多模态参考生成评测
在各项评测中,Seedance 2.0的综合表现达到行业领先水平。
不过,字节跳动也坦言,模型在细节稳定性、多人口型匹配、多主体一致性、文字还原精度和复杂编辑效果等方面仍有优化空间。从当前技术发展的角度来看,这些挑战反映了大模型在处理复杂场景时仍需进一步提升精准度与逻辑连贯性,尤其是在涉及多人物互动或高精度文本还原的任务中,表现尚不够成熟。这说明即便是在行业领先企业中,相关技术仍处于持续迭代阶段,未来仍有较大提升潜力。
官方表示,Seedance2.0目前仍存在诸多不足,生成效果仍有提升空间。未来,它将持续深入探索大模型与人类反馈之间的精准对齐,致力于打造更加高效、稳定且富有创意的音视频制作工具,为更多创作者提供支持。